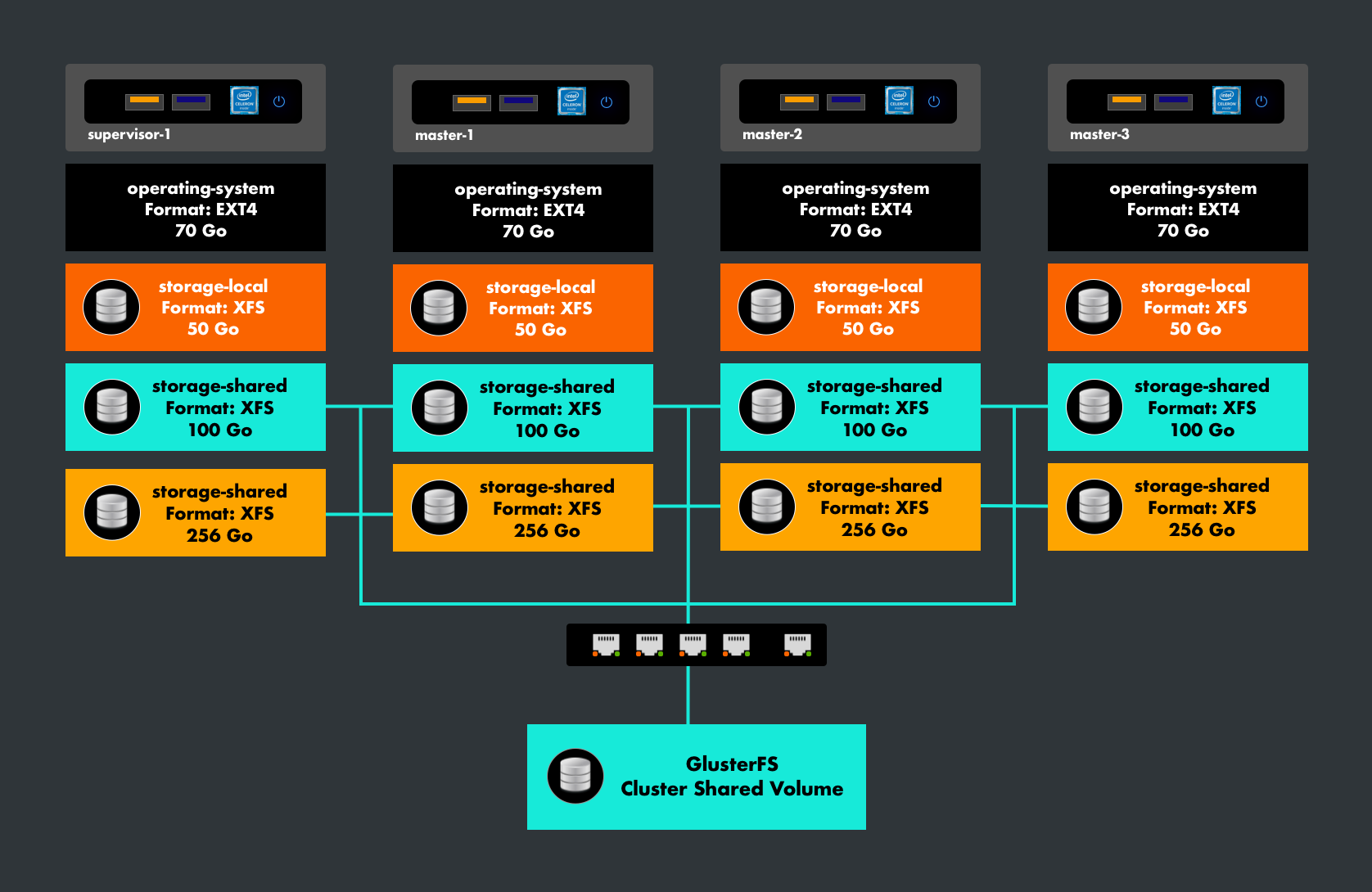
Masters
1. Introduction
The masters are replicated to ensure the high availability of the cluster.
In our infrastructure, we have 3 masters. These are the foundation of the Control Plane.
2. Control Plane Components
- kube-apiserver
A component on the master that exposes the Kubernetes API. It is the front-end for the Kubernetes control plane.
It is designed for horizontal scaling, meaning it scales by deploying additional instances. See Building Highly Available Clusters.
- etcd
A consistent and highly available key-value database used as a backup store for all cluster data.
If your Kubernetes cluster uses etcd as a backup store, make sure you have a backup plan for this data.
You can find more information about etcd in the official documentation.
- kube-scheduler
A component on the master that monitors newly created pods that are not assigned to a node and selects a node for them to run on.
Factors considered for scheduling decisions include individual and collective resource requirements, hardware/software/policy constraints, affinity and anti-affinity specifications, data locality, workload interference, and deadlines.
- kube-controller-manager
A component on the master that runs controllers.
Logically, each controller is a separate process, but to reduce complexity, the controllers are all compiled into a single binary and run in a single process.
These controllers include:
- Node Controller: Responsible for detecting and responding when a node goes down.
- Replication Controller: Responsible for maintaining the correct number of pods for every ReplicationController object in the system.
- Endpoints Controller: Populates Endpoints objects (i.e., joins Services and Pods).
- Service Account & Token Controllers: Create default accounts and API access tokens for new namespaces.
- cloud-controller-manager
The cloud-controller-manager runs controllers that interact with the underlying cloud providers. The cloud-controller-manager binary is an alpha feature introduced in Kubernetes version 1.6.
The cloud-controller-manager runs only the loops specific to cloud providers. You must disable these controller loops in the kube-controller-manager. You can disable the controller loops by setting the --cloud-provider flag to external when starting the kube-controller-manager.
The cloud-controller-manager allows the cloud provider code and Kubernetes code to evolve independently. In earlier versions, Kubernetes core code depended on cloud provider-specific code for functionality. In later versions, cloud provider-specific code should be maintained by the cloud providers themselves and linked to the cloud-controller-manager when running Kubernetes.
The following controllers have dependencies on cloud providers:
- Node Controller: For checking the cloud provider to determine if a node has been deleted in the cloud after it stops responding.
- Route Controller: For setting up routes in the underlying cloud infrastructure.
- Service Controller: For creating, updating, and deleting load balancers from cloud providers.
- Volume Controller: For creating, attaching, and mounting volumes, and interacting with the cloud provider to orchestrate volumes.
3. Architecture
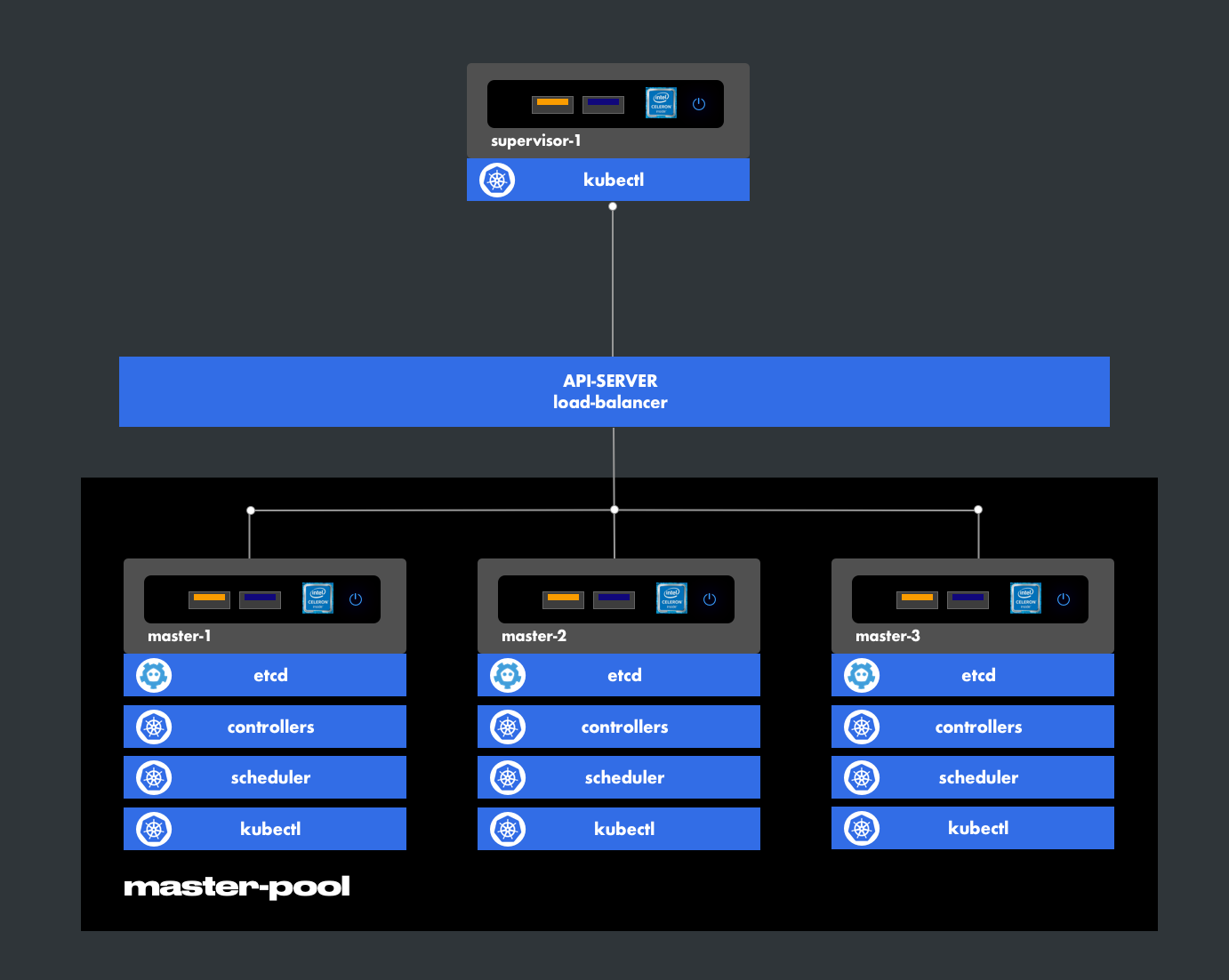
4. Roles
- master-pool
This group ensures the proper functioning of the control plane. - supervisor
This machine interacts with the apiserver to manage the control plane.
The manifests intended for deployments are stored on this host.
5. Networking
Interface:
- Kubernetes CNI
6. High Availability
6.1. Quorum Principle
Ref: Microsoft Learn
Quorum is designed to prevent split-brain scenarios that can occur when there is a partition within the network and subsets of nodes cannot communicate with each other. This can lead to both subsets of nodes attempting to take ownership of the workload and writing to the same disk, causing numerous issues. However, such a scenario can be avoided through the quorum concept of failover clustering, which forces only one of these groups of nodes to remain operational. This ensures that only one group remains online.
Quorum determines the number of failures the cluster can tolerate while remaining online. It is designed to handle communication issues between subsets of nodes in the cluster. It prevents multiple servers from simultaneously hosting a resource group and writing to the same disk at the same time. Through this quorum concept, the cluster forces the cluster service to stop on one of the subsets of nodes so that there is only one true owner for each resource group. Once the nodes that were stopped can communicate with the main group of nodes again, they automatically rejoin the cluster and restart their cluster service.
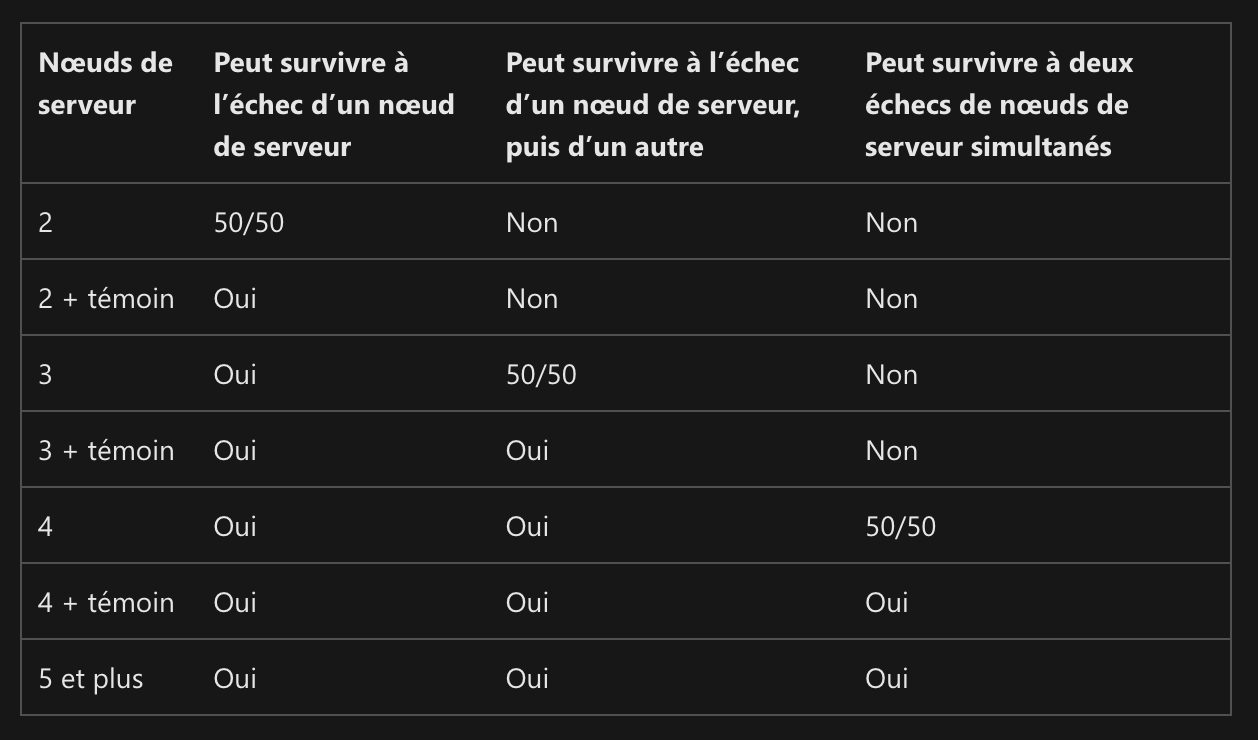
Cluster Quorum Recommendations
- If you have two nodes, a witness is mandatory.
- If you have three or four nodes, a witness is strongly recommended.
- If you have five or more nodes, a witness is not necessary and does not provide additional resilience.
- If you have internet access, use a cloud witness.
- If you are in a computing environment with other machines and file shares, use a file share witness.
6.2. ETCD Cluster
ETCD is Kubernetes' default database. It is a key-value database designed to store configuration parameters.
ETCD operates in a cluster, and its high availability is based on Quorum.
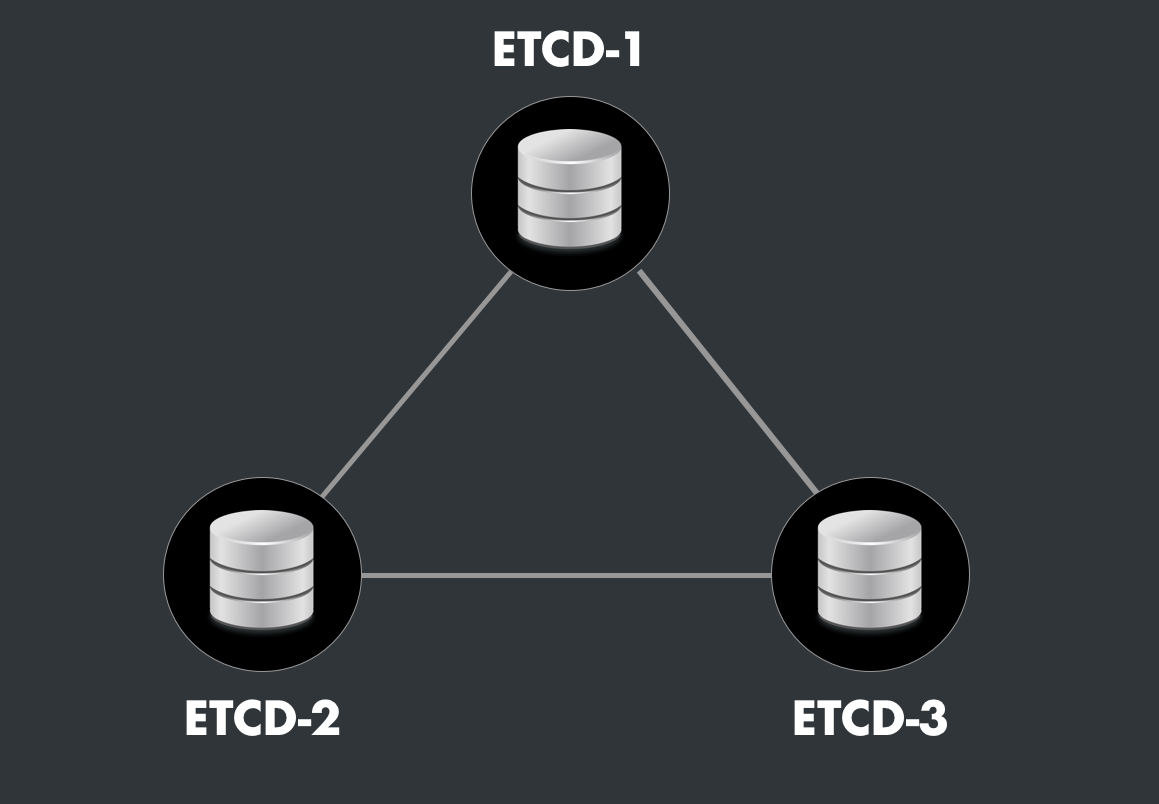
The high availability of Kubernetes depends not only on the number of control plane replicas but also heavily on the high availability of ETCD.
6.3. ETCD/Control Plane Relationship
Kubernetes implements two types of architectures for the ETCD/Control Plane relationship:
6.3.1. Stacked Etcd Cluster
In this architecture, each master includes its own database. Thus, the number of masters is strictly equal to the number of etcd instances. In this case, the quorum principle applies to the number of masters.
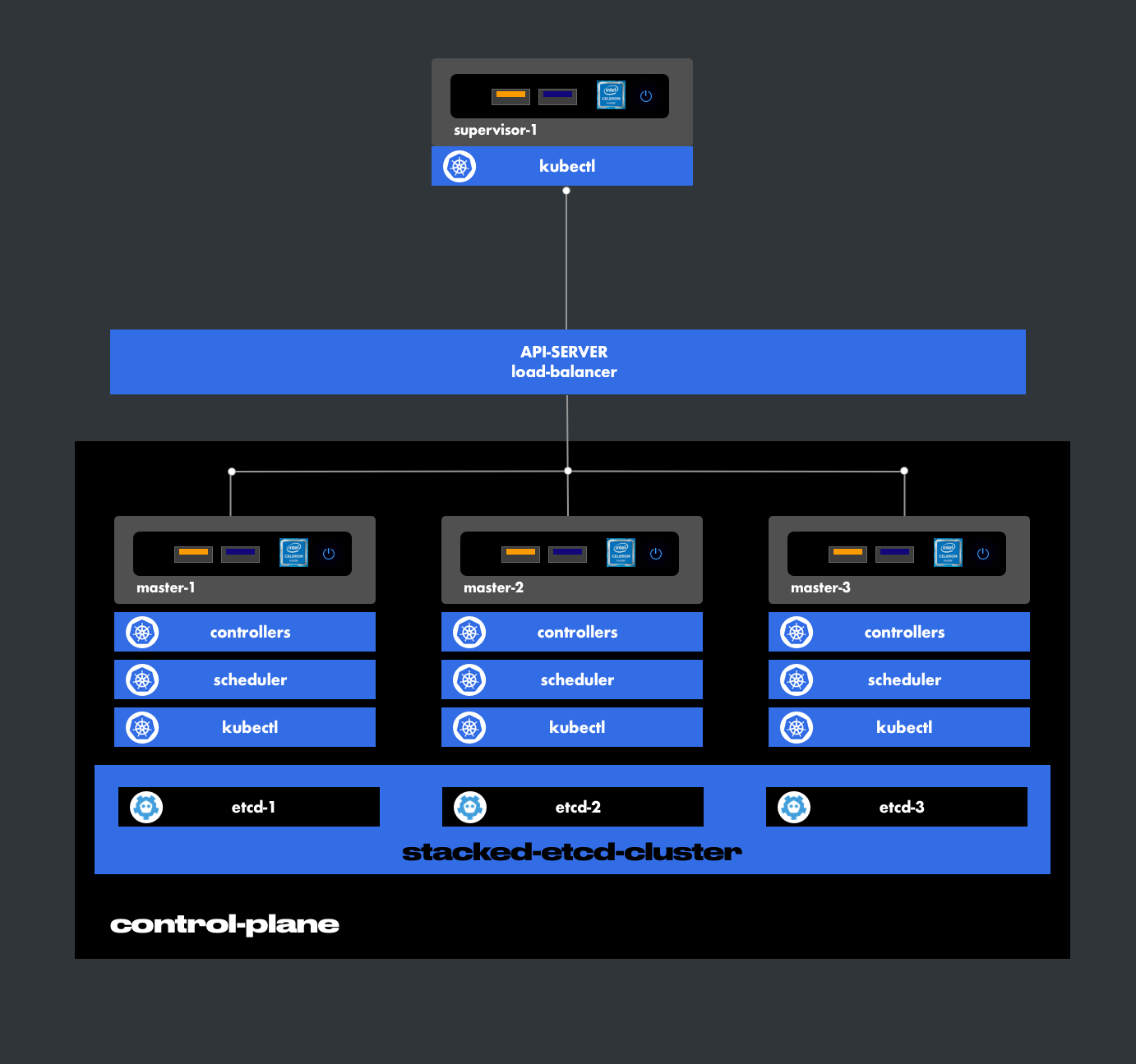
Availability Condition
For three nodes, the quorum majority is 2. This is the number below which the cluster becomes unavailable.
Quorum Table for 3 Nodes
| Nodes in Service | Nodes Out of Service | Majority | Availability |
|---|---|---|---|
| 3 | 0 | 3 | UP |
| 2 | 1 | 2 | UP |
| 1 | 2 | 1 | DOWN |
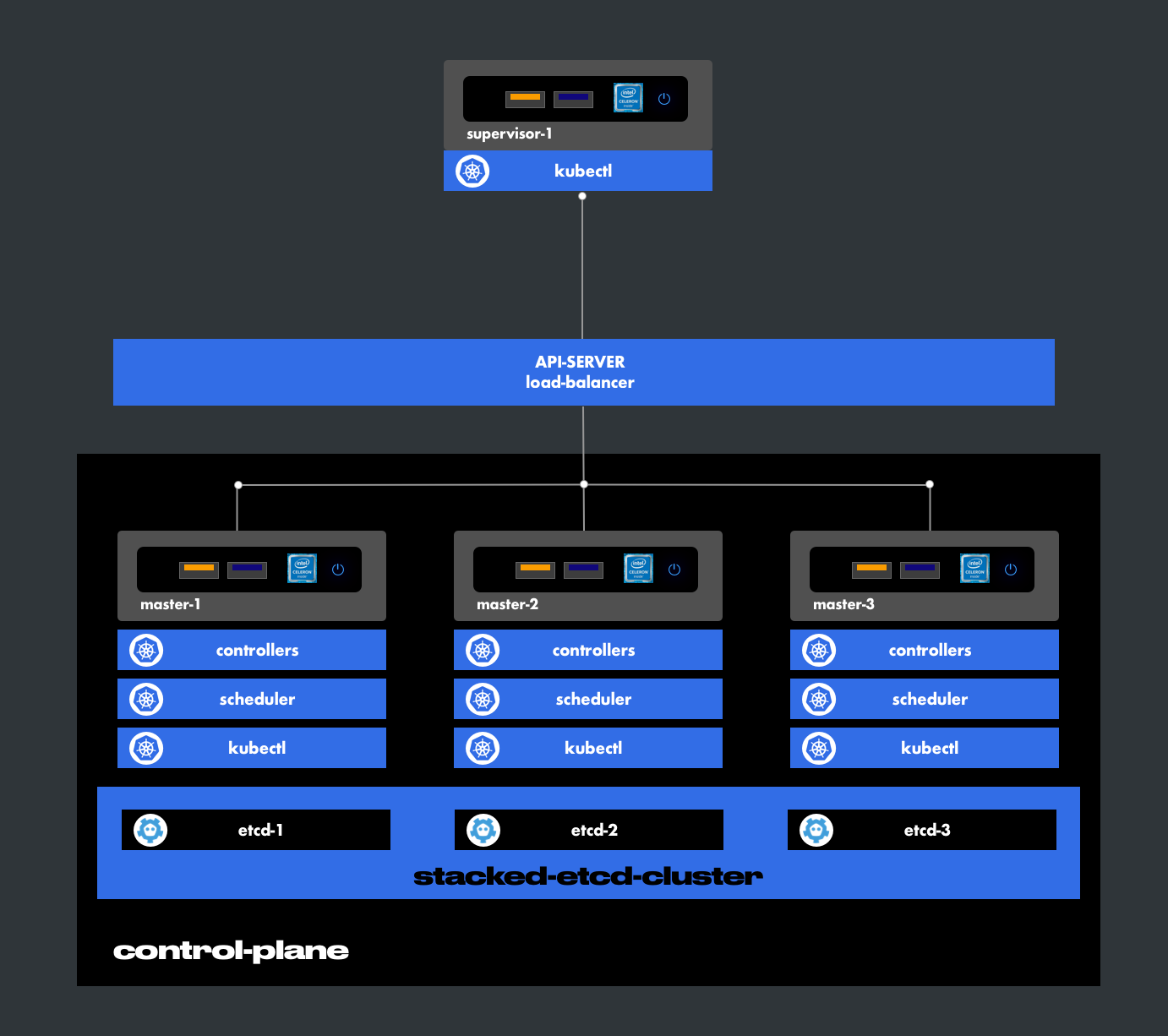
6.3.2. External Etcd Cluster
Externalizing the etcd databases allows extending the quorum majority (the number of instances in service). This architecture improves high availability without adding additional masters. This model adds a layer of security and makes maintenance more flexible.
Example: ETCD with 3 instances
Example: ETCD with 6 instances
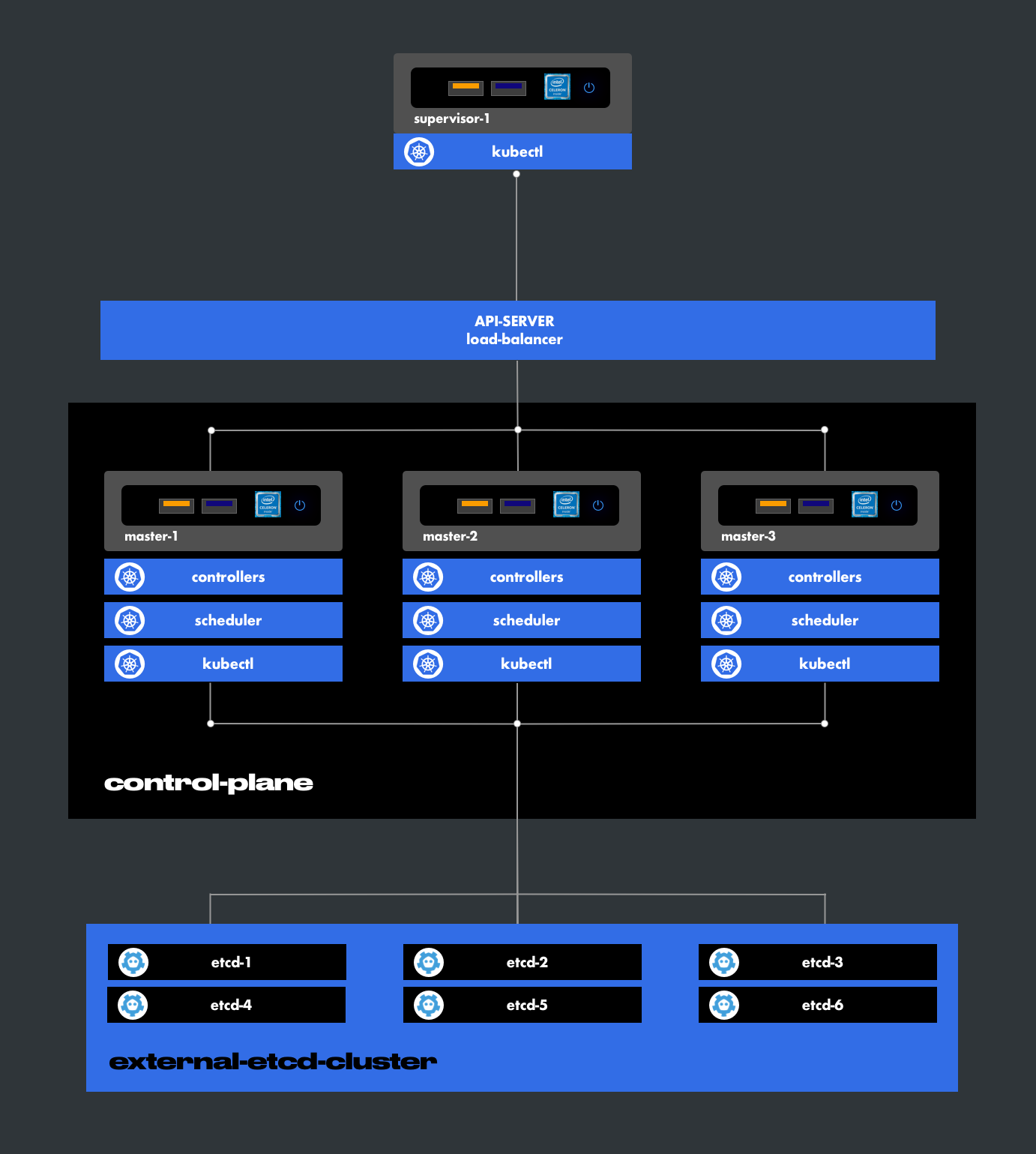
Quorum Table for 6 Nodes
| Nodes in Service | Nodes Out of Service | Majority | Availability |
|---|---|---|---|
| 6 | 0 | 6 | UP |
| 5 | 1 | 5 | UP |
| 4 | 2 | 4 | UP |
| 3 | 3 | 3 | UP |
| 2 | 4 | 2 | DOWN |
| 1 | 5 | 1 | DOWN |
6.3.3. Infrastructure's ETCD Architecture
Our choice is the stacked etcd cluster, which meets high availability standards.
7. Volumes